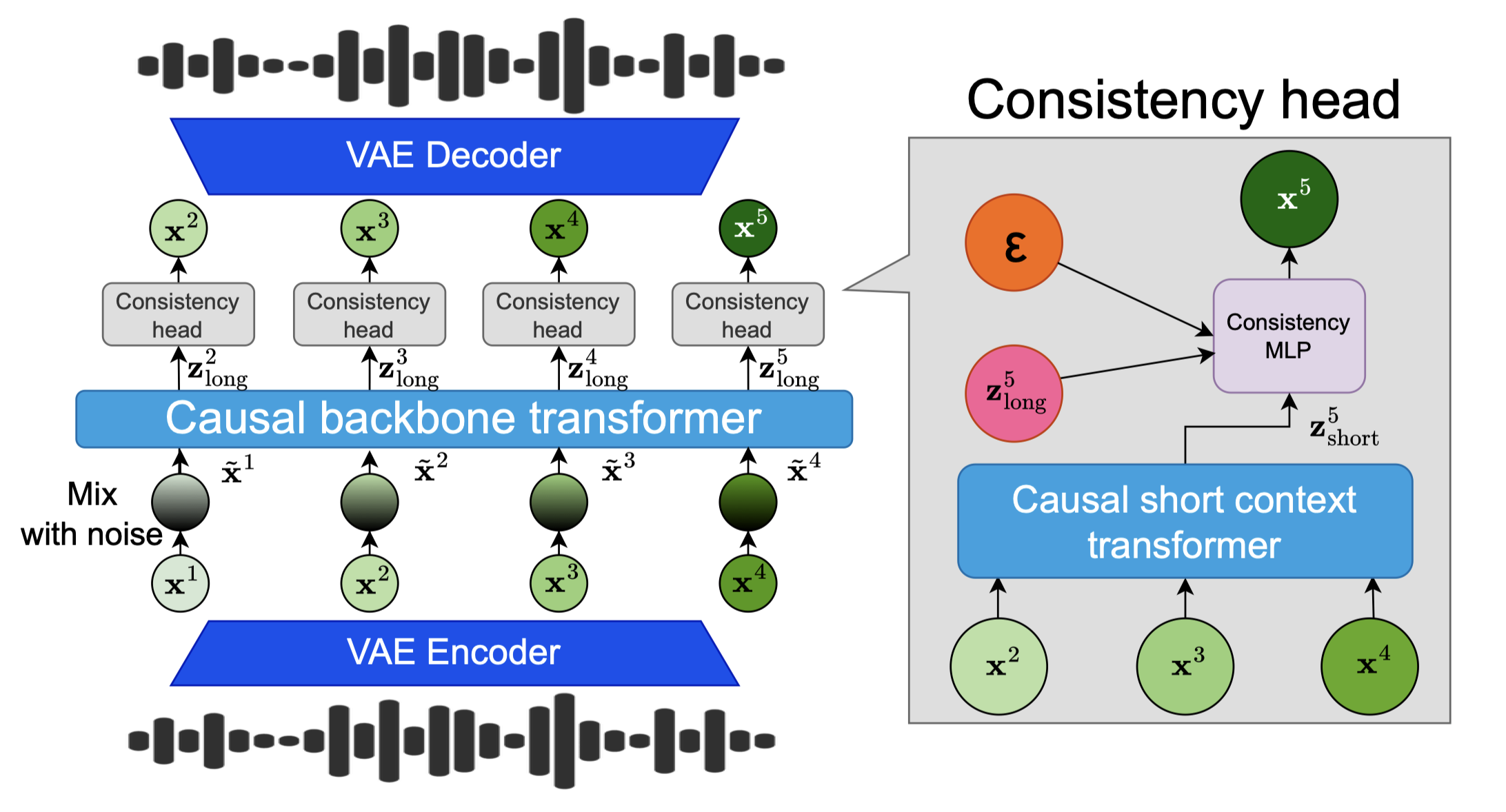
Audio Language Models (ALM) have emerged as the dominant paradigm for speech and music generation by representing audio as sequences of discrete tokens. Yet, unlike text tokens, which are invertible, audio tokens are extracted from lossy codecs with a limited bitrate. As a consequence, increasing audio quality requires generating more tokens, which imposes a trade-off between fidelity and computational cost. We address this issue by studying Continuous Audio Language Models (CALM). These models instantiate a large Transformer backbone that produces a contextual embedding at every timestep. This sequential information then conditions an MLP that generates the next continuous frame of an audio VAE through consistency modeling. By avoiding lossy compression, CALM achieves higher quality at lower computational cost than their discrete counterpart.
On this webpage, we show some results of our speech model as well as our music models. We illustrate as well the ablation study of the paper with some music samples.
Speech Language Model
This section presents speech samples generated using a 3-second prompt. Key details of the setup and results include:
Starting from a Helium pretrained 2B parameters text language model [1], we adopt the inner monologue framework from [2], where the model is fine-tuned with an audio stream delayed by 80 ms after the textual stream.
CALM setting: Audio stream is composed of continuous latents predicted via 1-step consistency modeling.
RQ-Transformer setting: Audio stream is produced using an 8-RVQ Mimi Codec and predicted in parallel by an RQ-Transformer.
Performance: CALM outperforms RQ-Transformer on meaningfulness. We believe this may be due to the backbone allocating less capacity to audio manipulation, leaving more for text prediction in the CALM setting. As well, we can see that temperature has a huge impact for both models, validating our heuristic for temperature sampling for CALM.
Efficiency:
Sampling each latent from the consistency head is 12.3× faster than with the RQ-Transformer.
Generating 30 seconds of audio is overall 1.3× faster with CALM than with the baseline.
Prompt
RQ-Transformer 8 RVQ temp=0.8 (baseline)
CALM Consistency 1 Step temp=0.8
CALM Consistency 1 Step temp=1.0
RQ-Transformer 8 RVQ temp=1.0
Music Generation
We compare our music generation models, all of which use a backbone with 1.35B parameters (from MusicGen Medium):
Baseline: RQ-Transformer with 32 RVQ.
CALM with TrigFlow (100 steps): Slower inference than the baseline.
CALM with Consistency (4 steps): Inference is 1.9× faster than the baseline.
CALM with Consistency (1 step): Inference is 2.1× faster than the baseline.
Retrained MusicGen [3]: Trained on our dataset, with inference 1.3× faster than the baseline.
Prompt
RQ-Transformer 32 RVQ (baseline) FAD: 1.06
CALM TrigFlow 100 steps FAD: 0.64
CALM Consistency 4 steps FAD: 0.71
CALM Consistency 1 step FAD: 0.83
Retrained MusicGen FAD: 1.72
Ablation Study
We illustrate here the ablation study of our paper in order to show the importance of each component of our model. We showcase it on Music Generation with CALM Consistency 4 steps. All the models have been trained 300k steps instead of 500k steps.
Our model with Noise Augmentation, Short Context transformer and Head Batch Multiplier. CALM Consistency 4 steps.
Without Noise Augmentation, Short Context transformer and Head Batch Multiplier. This configuration is very close to MAR [4]. It consists in just replacing the codec by a VAE and replacing the RQ-Transformer head by a consistency model. This model suffers from error accumulation, doesn't generate consistent music and tends to diverge (distorsion quickly happens).
Without Short Context Transformer. Here, the addition of Noise Augmentation makes the model less sensitive to error accumulation. However, it quickly stops generating details focuses on the rhythmic and fades away during generation. This configuration is similar to the one used in [5] where the authors generate short single instrument music.
Without Noise Augmentation. Here, there is no Noise Augmentation at training time but there is the Short Context Transformer that greatly helps the model to generate details. However there is still some error accumulation (see the 3rd sample).
Without Head Batch Multiplier. Here, the model convergence is slower, its quality is lower for the same number of epochs.
Prompt
Our Model
Without Noise Aug., Short Context Transformer, Head Batch Mult.
Without Short Context Transformer
Without Noise Aug.
Without Head Batch Mult.
References
[1] Kyutai "Helium 1: a modular and multilingual LLM"website, 2025.
[2] Défossez, A., Mazaré, L., Orsini, M., Royer, A., Pérez, P., Jégou, H., Grave, E., & Zeghidour, N. (2024). Moshi: A speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037. Available at: https://arxiv.org/abs/2410.00037
[3] Copet, J., Kreuk, F., Gat, I., Remez, T., Kant, D., Synnaeve, G., Adi, Y., & Défossez, A. "Simple and Controllable Music Generation."arXiv:2306.05284, 2023.
[4] Li, T., Tian, Y., Li, H., Deng, M., & He, K. (2024). Autoregressive Image Generation Without Vector Quantization. arXiv preprint arXiv:2406.11838. Available at: https://arxiv.org/abs/2406.11838
[5] Pasini, M., Nistal, J., Lattner, S., & Fazekas, G. (2024). Continuous Autoregressive Models with Noise Augmentation Avoid Error Accumulation. arXiv preprint arXiv:2411.18447. Available at: https://arxiv.org/abs/2411.18447